Множимо галюцинації: есе про нову ШІ-реальність
Множимо галюцинації: есе про нову ШІ-реальність
Набір моїх спостережень про те, що відбувається з нами за останні кілька років і куди це все може рухатися.

Базове слово це “нестабільність”.
ШІ всюди, як раніше “крипта”
Основні компанії, що займаються штучним інтелектом, взяли на озброєння термін AGI (загальний штучний інтелект) і кожні кілька місяців заявляють, що ми вже майже там. Що практично завтра багато робіт ШІ зможе виконувати сам, при цьому проводячи складні наукові дослідження та експерименти і на рівні не середніх, а дуже розумних людей.
У світі може бути чергова технологічна “бульбашка”. Можливо, ажіотаж викликаний величезними вливаннями грошей у маркетинг, а не стільки функціональністю. Впровадження та підтримка систем ШІ є занадто дорогими та складними для багатьох організацій. Зараз відбуваються величезні вливання ресурсів у встановлення нового обладнання, збір та очищення даних, тренування моделей, розгортання інфраструктури — все заради “світлого майбутнього”. А також залучення людей в саме таке майбутне.
Ще з 1970-х прийшла фраза “10х розробник”, яку зараз підхопили багато гучних заголовків, мовляв ШІ збільшує продуктивність програміста в 10 разів.
Немає гарантії, чи виправдаються інвестиції і чи взагалі потрібно це робити кожній конкретній компанії. Той самий проєкт “Stargate” не має чіткого майбутнього, вони просто будують величезні простори обчислювальних потужностей — а керує проектом Чейз Лохміллер (Chase Lochmiller), який піднявся на майнінгу біткоїнів.

відео про це https://www.youtube.com/watch?v=GhIJs4zbH0o
Як і з майнінгом, після запуску ці місця почнуть споживати величезну кількість енергії, води — а до запуску виробництво всіх чіпів ще залишить значний CO2 слід. Створення таких дата-центрів має й екологічну вартість для планети.
До кінця не зрозуміло, чи отримує хтось із великих гравців ринку прибуток зараз. Хоча, якщо OpenAI перестане тренувати нові моделі і на безкоштовному плані залишить по 3–5 повідомлень на день, вона, думаю, швидко стане прибутковою.
Точно і легко заробляє десятки мільйонів доларів на реєстраційних зборах крихітна острівна держава Ангілья, якій належить домен “.ai” :)
Багато хто з продавців ШІ сподівається, що незабаром люди вже не зможуть жити і працювати без їхніх моделей. Поки що намагаються набирати гроші інвесторів або перепродаватися один одному. Обіцяється, що в світлому близькому майбутньому потрібно буде мати величезні обчислювальні потужності, щоб запускати на них ШІ агентів і нарешті позбутися цих неприємних і примхливих людей-працівників.
Є, звичайно, повідомлення про використання ШІ для наукових відкриттів, оптимізації дата-центрів і створення ліків, але я б відніс це скоріше до сфери успіхів бізнес дата-саєнс.
Фундаментально не ясно і де межі можливостей поточної архітектури нейромереж “Трансформер” (GPT) — що вона може робити, що вона не може і чи зможемо ми зменшувати кількість неправильних спрацьовувань.
Галюцинації — не баг, а фіча
За останні років так 70 звикли, що комп’ютер на гіпотетичне “2+2” видає “4”, а ось поточні Великі Мовні Моделі (ВММ (LLM) на архітектурі “Трансформер”, generative pre-trained transformer (GPT)) додали до цього, що комп’ютер тепер буде видавати не тільки 4.
Одна з фундаментальних проблем ВММ — їхня схильність генерувати неправдиву або неточну інформацію (“галюцинації”), не позначаючи її як таку.
Саме навчання мовних моделей заохочує галюцинації на базовому рівні, тому що моделі завжди повинні давати припущення про наступне слово. Неправильні фактично, але правильно лінгвістично сформульовані відповіді — це не збій, а наслідок нашої технології.
На одне й те саме питання при кожній генерації відповідь генерується штучною нейромережею з нуля тут і зараз, і немає жодної гарантії, що вона буде такою ж, як при минулій генерації. Моделі працюють насамперед на основі статистичних асоціацій, виявлених у даних, і тому не варто від них очікувати того, що ми очікуємо від “калькуляторів” CPU/GPU.
Також немає надійного зовнішнього загального механізму перевірки достовірності сгенерованих відповідей. Це “обмежує” (поставлю лапки, оскільки сучасним стартапам все одно, і про це ще напишу) застосування ВММ в областях, де точність є критично важливою, як-от медицина, психіатрія чи фінанси.
У спрощеному вигляді ВММ кілька років описувалися вченими як дуже складні системи автозаповнення, що передбачають наступний шматок слова/коду на основі завченого величезного обсягу даних. Але після звіту Anthropic про дослідження “мислення” їхньої моделі Claude ми зрозуміли, що вона використовує внутрішню мову і відповідає в кінці перекладом з неї, іноді не те, що всередині думає — навіть у режимі опису мислення по кроках.
див звіт https://www.anthropic.com/research/tracing-thoughts-language-model
Після навчання ВММ напрацьовується внутрішній механізм запобігання галюцинаціям, який схожий на управління самовпевненістю у людей. Галюцинація трапляється, коли відбувається “збій” (misfire) схеми “відомої відповіді”. Щойно модель “вирішила”, що їй потрібно відповісти на питання (тому що відмова була пригнічена), вона починає “вигадувати” (confabulate) — генерувати правдоподібну, але фактично невірну відповідь.

Як і за часів золотої лихоманки, найбільше заробляють не ті, хто шукає золото, а ті, хто продає лопати. Це NVIDIA з її чіпами та навколо цього всі хмари обчислень.
Варто звернути увагу, що компанії, які продають доступ до AI-моделей, нам фактично продають гарантію обчислювальної потужності (compute), а не гарантію корисності чи правдивості відповіді. Вони тихо і хитро уникли відповідальності, перекинувши її на користувачів, “які не перевірили”.

Вайб-кодинг та деградація розуміння
У 2025 році “програмісти стають перевіряльниками коду”: якщо раніше більшість часу йшла на написання коду, то тепер код генерується ШІ як хороший, так й поганий (це легко відразу побачити), так і невочевидь помилковий.
Зміщується акцент у роботі розробника з написання коду на його валідацію, рефакторинг, проєктування архітектури, управління складністю та визначення проблем. Більшість розумових зусиль йде на стеження за тим, “що ШІ наробив”.
Чи потрібно глибоко розуміти, як працює код або текст, згенерований AI, чи достатньо вміти отримати потрібний результат за його допомогою?
Чим ширше в суспільство впроваджується використання ШІ для генерації готових відповідей, тим гірше може ставати з суспільним активним розумінням реальності, її процесів. Це може зашкодити в цілому багатству культури, рівню інновацій та технічному прогресу.
Так, з подачі твіту Андрія Карпати (https://karpathy.ai/) з’явився феномен “вайб-кодингу” (вікіпедія), коли творцеві загалом все одно, як працює всередині його програма. Просто кажеш ШІ, що зробити, і коли програма працює “не так”, як хотів, то ще кажеш йому це виправити і т.д. — швидше за все, призводить до дуже заплутаного і нестабільного “спагеті” коду, який нашарувався багато разів.

Створена так програма-сайт теж перетворюється на щось подібне до імовірнісної поведінки ШІ: ти не знаєш, де вона працює правильно, а де неправильно — де в неї проблеми з безпекою або ще чимось.
Ця програма-сайт хоч і ВИГЛЯДАЄ як та, до якої ми звикли, всередині має іншу сутність. Не стабільно перевірену продуману, а якось згенеровану зліплену.
Повернення інтерфейсу до дографічного
Ми всі десь з 1985 року використовуємо GUI, тобто графічний інтерфейс, щоб зрозуміти, як читати сайт або фотошопити зображення. Комп’ютери багато років змушують нас маніпулювати даними, щоб дістатися до бажаного результату, і під це навіть був придуманий окремий маніпулятор — миша.
А сайти візуально керують подачею, щоб переконувати і викликати довіру до товарів і послуг.
Поки що ші-агенти мало розвинені, і можна дивитися маркетингові криві демонстрації: вам замість того, щоб лазити по сайтах і шукати собі квиток на матч, можна просто сказати ШІ-чату зробити це, зафіксувати ціну, і він буде там продиратися, в кінці просто повідомить результат.
ШІ-агентам не потрібен увесь цей інтерфейс, і вони вчаться працювати з ним тільки тому, що ми так побудували інтернет-світ “під людей”. Але MCP (https://modelcontextprotocol.io/), думаю, зможе це вирішити, і вони просто будуть через нього “говорити” з сайтом або програмою.
Оскільки ми все одно не можемо зрозуміти, як ШІ нам згенерував цю відповідь, то в результаті нам загалом стає все одно і на візуалізацію процесу отримання та даних, що стоять за ним.
Часто “спілкування” з ШІ подано у вигляді особистого листування один на один, що провокує довіру користувача до “магічно” з’являючихся відповідей. Можна змусити його зливати куди більш особисті дані.
Коли з’явився ChatGPT та інші сервіси роботи з ШІ, вони не створювали ніяких візуалізацій. Виглядають просто як чат двох людей. В аудіорежимі це взагалі схоже на розмову двох людей з кружечком посередині екрана.
ШІ зараз “з’їдає інтерфейс”. Ми в чомусь відкотилися до того моменту, коли з комп’ютером спілкувалися через текстовий термінал.

Звичайно, тепер у нас вже є гібрид пошуку і чату, де до відповідей додають посилання на джерела, звідки це взято. Також ChatGPT вже вміє виводити віджети погоди, акцій, рахунків матчів і т.д. Є і “запуск коду”, коли модель не буде генерувати відповідь на “2+2”, а згенерує невелику python-програму, отримає від неї відповідь і видасть її.
Андрій Карпати ще казав, що “тепер мова програмування — це англійська”. Ідея, яку тут просувають, що нам у найближчому майбутньому не треба буде заходити на сайти, запускати програми, створювати ці сайти і програми — замість цього нам просто треба буде розповісти ШІ, що нам треба, і отримувати бажаний результат (швидше за все, не розбираючись, як він отриманий!).
Візуалізація — це для людей
У статті від Остіна Паркера піднімається питання зміни в Observability. Це поняття можна перекласти як “спостережуваність” і здатність зрозуміти внутрішній стан системи, просто досліджуючи дані, які вона видає назовні (логи, метрики, трасування).
Традиційні інструменти спостережуваності останні десятиліття концентрувалися на тому, як зробити величезні обсяги різнорідних даних-звітів зрозумілими для людини, створюючи дашборди, сповіщення та методи вибірки для “стиснення” інформації, що подається.
Автор стверджує, що великі мовні моделі починають призводити до “смерті парадигми Observability”, генеруючи і перевіряючи гіпотези швидше за людину — прямо з сирих даних.
Якщо цінність продукту заснована лише на графіках і простій інструментації, то він приречений, оскільки модель робить припущення з аналізу, не “дивлячись” у ці графіки. При цьому нові моделі можуть і дивитися, у них є розпізнавання зображень, але навіщо, якщо це тільки сповільнює.
Як приклад наводиться демонстрація Honeycomb: ШІ-агент на основі ВММ (Claude Sonnet 4) зміг за 80 секунд і 60 центів проаналізувати “дивні сплески затримки” у фронтенд-сервісі. Агент самостійно ідентифікував причину (тестування продуктивності, проблеми з сервісом оформлення замовлення, затримки розрахунків знижок і доставки) і запропонував рішення.
У майбутньому автор думає, що агенти працюватимуть у фоні і самостійно пропонуватимуть поліпшення коду, виявлятимуть і виправлятимуть аномалії систем без необхідності нам мати дашборди.
Детальніше у статті https://www.honeycomb.io/blog/its-the-end-of-observability-as-we-know-it-and-i-feel-fine — також вже є напрацювання розвивати такі продукти, як-от https://docs.cursor.com/bugbot
Я ж це ще узагальню: більшість людей, які працюють з даними, використовують візуалізації як спосіб швидше зрозуміти структуру і можливі напрямки роботи. Я навіть не думаю, що без візуалізації можлива така робота, багато замовників хочуть в кінці не просто рекомендацію, а й пояснення на слайдах, чому саме це.
Ще більш глибока проблема — зміна сутності роботи, працівника і найму. Читаю HR-блог: деякі кандидати тепер очікують, що їх візьмуть на роботу за виданий результат, а не за пояснення і глибоке розуміння процесу його отримання (наприклад, написання статей або коду) і докази стабільності на основі цього.
Деградація інтернету як датасету
Мені цікаво досліджувати нові стартапі. Останій рік все частіше бачу, що у них на маркетинг сайтах щось з’їжджає і криво виглядає, або криво адаптовано для телефону. Страшно подумати, а що там у продукті. Швидше за все, вони просто згенерували все, виставили там кнопку “давай 20 доларів/місяць” і не вклалися в перевірку, якість і стабільність.

І це не тільки сайтів стосується, з усіх боків поступово починає вилазити швидко і “брудно” згенерований “ШІ-мотлох / AI slop”. В основному це роблять “індуси” та інші малоосвічені люди в гонитві за невеликим прибутком, хоча “найрозумніші” продають “курси”, як заробляти на ШІ-мотлоху, що породжує його ще більше.
Детальніше у відео: https://www.youtube.com/watch?v=Cedj8AKI2U8
При появі інтернет з’єднував ВНЗ і лабораторії вельми розумних, креативних і передових людей. З впровадженням Windows 95 і спрощенням використання комп’ютера все більше звичайних людей стало підключатися, але все ще вони не могли “гадити” в мережу, і тільки з розвитком феномену “веб 2.0” після 2005 року, де контент створюють користувачі без відповідної експертизи, ми почали котитися вниз (загалом, а в конкретних випадках це, звичайно, дозволило вести блог дуже вузьким нетехнічним фахівцям), а потім й фейсбук-інста-тікток.
Великі мовні моделі для свого навчання потребують величезних масивів даних, які до недавнього часу бралися просто з копії всього відкритого інтернету. Звичайно, там був мотлох, але не в такому співвідношенні.
Тепер же ми підключили до створення наповнення Інтернет не тільки малоосвіченого користувача, а й ШІ з мінімальною фільтрацією — швидкість засмічення піднялася в рази. Мережа стрімко наповнюється текстами, зображеннями та кодом, згенерованими нейромережами.
Виходить велика загроза для майбутнього ШІ — це сам сьогоднішній ШІ і способи його безвідповідального використання. Схоже на створення ксерокопії з ксерокопії з ксерокопії з ксерокопії з ксерокопії і т.д. — з кожним циклом якість падає, деталі губляться, а спотворення накопичуються. Реальні якісні дані стають все ціннішими.
Падає якість саме смислового навантаження та опису реального світу, а ось технічна якість згенерованих текстів, аудіо, зображень (відео поки не дотягують) стрімко зростає, і вже складно відрізняти фото реальні від згенерованих. Це ж ускладнює і перевірку програмістами згенерованого коду, тепер не відразу очевидно, що він помилковий.
З того, що у мене накопичується відчуття деградації контенту, я все менше використовую пошуковик по сайтах Інтернету і взагалі не використовую соціальні мережі — все більше переходжу тільки в чати: або з людьми, або з ШІ.
Немарковане походження
Ще обурює, коли, маючи проблему, заходиш в чат підтримки на сайті компанії (наприклад, інтернет-провайдера), починаєш діалог з, наприклад, “Світланою”, і тільки коли приходять якісь дивні шаблонні відповіді, розумієш, що це ШІ-чатбот. Добре, якщо він відразу визнає, що він бот, і переключає на людину.
Поступово легко-швидко згенерований ШІ контент починає витісняти той, що пишуть/записують/знімають реальні люди.
Зустрічав ідею стартапів, створити соціальну мережу “реаліті-ТВ”, в якій взагалі неможливо писати безпосередньо, а тільки генерувати. Там будуть згенеровані персонажі проживати своє згенероване життя для нас.
При всьому бажанні якось вставляти “водяні знаки” в згенерований ШІ контент, люди зараз публікують багато непідписаного. На YouTube мені трапляються все більше освітніх “пояснюючих” каналів, відео на яких згенеровані повністю, як зміст, так і голос озвучки.
Можливо, і частина коментарів під цим відео залишені ботами, оскільки мені дивно, якщо ці захоплення пишуть реальні люди.

Контент-параноя. З підвищенням якості генерації у мене постійно виникає питання, дивлячись новини, “а чи не згенеровано це?”.
Колись було легше згенерувати зображення/голос тільки тих людей, чиїх зображень/голосу в мережі вже багато, але сучасні системи вже справляються і з парою фото і декількома секундами голосу як вихідним матеріалом.
Наприклад, якщо у нас є дві ворогуючі групи, то одна з них може генерувати кілька фото людини своєї групи в зрозумілих візуальних знаках, що вона своя (одяг і т.д.) — на одному фото вона мила з собачкою/котиком, а на іншому в лікарні вся в синцях і трубках. Ну і підпис (а) побила інша група (б), гроші скидати сюди.
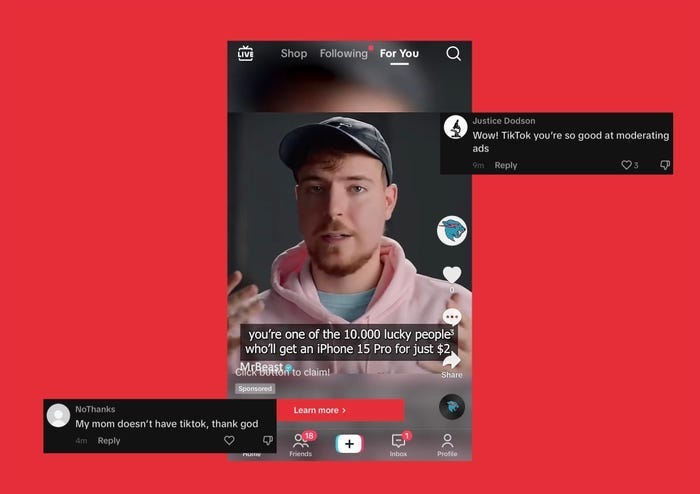
В соціально-політичній сфері це вже становить загрозу нацбезпеці, оскільки використовується не тільки як шахрайство для виманювання грошей, а й для дискредитації опонентів і розпалювання групових конфліктів.
Йде поступове зниження базової суспільної довіри до контенту в інтернеті та ЗМІ.
Чим досконаліші технології генерації, тим менше ми можемо довіряти інформації в принципі. Тепер реальність “описує” той, хто швидше “затоплює” інтернет певними описами. При цьому “голоси” справжніх людей стають менш помітними, адже їх “перекрикують” ці фабрики генерації.
Якщо все триватиме в такому дусі, то читання інтернету стане не як документальних, а як художніх творів.
Втома від ШІ-хелперів
Просто з усіх боків йде боротьба “за клієнта”, щоб агресивно впарити ШІ-помічників. У мене раптом виникає відчуття, що я приїхав на вокзал в Індію, і на мене раптом на виході накинулися 50 хелперів, що кричать одночасно наперебій, пропонуючи “недорогі” порожні послуги.
Нещодавно мій браузер Firefox увімкнув мені спливаюче вікно, через яке я можу виділений текст кинути в ШІ-чат у бічній панелі.
Це, звичайно, було очікувано, але далі Notion, офісні додатки Google та різні інші сайти “покращіли” свій інтерфейс, щоб мати всі свої кнопки “використовувати ШІ” на видному місці. У новому MS Office іноді цих кнопок три на екран. У нових ноутбуках Copilot ще винесений як окрема кнопка на клавіатурі.
Усе це показано у відео https://www.youtube.com/watch?v=oXtvAQ-e0iE
Також на рівні ОС у Windows раптом з’явився окремий Copilot (або можна поставити програму від ChatGPT, а я використовую Cheery Studio), що додасть ще одну гарячу клавішу, кнопку і спливаюче вікно на виділене. Я, звичайно, все це відключив, а на Notion накинув userstyle, але для недосвідченого користувача у нього буде одночасно купа відволікаючих кнопок “використовувати ШІ”.
Багато виробників телефонів зараз на рівні Android вставляють взаємодію з ШІ. Виникає відчуття, що тепер в ІТ “без ШІ” нічого й продати користувачеві не можна. У Apple великі проблеми з їхніми рекламами нової Siri, якої по факту немає. Вони на важкому досвіді кривих самарі зрозуміли, що впровадження ВММ на величезну кількість людей призведе до величезної кількості помилок.
Так само щодня з’являються десятки ШІ-стартапів (огорток великих хмарних провайдерів), які відразу і прямо вимагають з тебе 20$/місяць за: поради щодо їжі, бігу, генератори ідей для бізнесу, помічники-дівчата-друзі-наставники, і т.д.
Притому ці помічники дії людей замінити і не можуть: у мене досить часто кнопки не дають бажаного автоматизованого результату, а просто призводять до злості, коли роблять не те, що мені потрібно.
Цей автоматичний агент, звичайно, пише код, але потім через кілька ітерацій “випадково” видаляє деякі працюючі файли та забуває вдалі рішення, і так по колу — результат ніби є, але ще більше є роздратування.
“Мені простіше самому”
В ІТ за останні два роки звичайні “вручну” програмісти — це меншість. Згідно з опитуванням Stack Overflow Developer Survey 2024, 76% (у 2023 було 70%) всіх респондентів або вже використовують, або планують використовувати інструменти ШІ у своєму процесі розробки.
Часте спілкування з непередбачуваним ШІ-чатом, крім того, що знижує критичне мислення, так само може замінювати спілкування з реальними людьми. Це призводить до посилення почуття самотності та зниження соціалізації.
Є такі люди, які просто принципово не будуть використовувати ШІ, тому що вони зайняли таку ціннісну позицію: “мені швидше самому з нуля зробити креативно і якісно, ніж мучитися з ШІ-галюцинаціями/непередбачуваністю і переробляти, і переробляти, і переробляти”.
Їхні аргументи за відмову — якість генерації нижча, ніж у рекламних матеріалах і спокусливих промовах власників ШІ-компаній. Будь-який новий анонс підкріплюється таблицею, в якій нова модель у всьому краща.
При цьому реальні кейси всі вирішують однаково посередньо. Усереднені листи, середньої якості код.
Ті, хто використовують генерацію, продукують “середні” за всім відповіді і самі не думають. Швидше за все, з часом можуть впасти в залежність від ШІ, не тренуючи навичку самостійного мислення. MIT Media Lab: піддослідні демонстрували нижчу мозкову активність у зонах, пов’язаних з пам’яттю, креативністю та когніцією, а їхні тексти були менш оригінальними.
Алгоритму генерації по суті немає, є непрозорий “чорний ящик”, який ми не розуміємо. За “чорним ящиком” часто ще прикривається і ховається вирівнювання, адже саме чат-модель — це мовне перенесення відносно невеликої кількості якісних знань, і які саме знання (цінності, політичні ідеї) будуть пріоритезовані ВММ, обирає компанія і первинна група людей (Reinforcement Learning from Human Feedback). Саме вони розмічають, які відповіді моделі доречніші.
Розум у машині
“ШІ все знає”. Хоча сучасні ВММ навчаються на копії всього відкритого інтернету, це те ж саме, що ми навчалися колись на “Букварі”, але чи знаємо ми його. З одного боку, так, я знаю всі літери, а з іншого боку, я не те що “на 6 сторінці в 8 абзаці” було, відповісти не можу, я жоден параграф, що там був, точно переказати не зможу. Хоча якийсь один популярний віршик, може, і зможу. Тому просити у ШІ цитати — це часто програшна справа, якщо у нього немає доступу до пошуку.
“ШІ об’єктивний і неупереджений”. Ні, оскільки і базове навчання відбувається на даних від людей (які схильні до упередженості та баєсів), і після компанії дотреновують (вирівнюють) моделі, щоб ті давали пріоритет певним типам відповідей. Забезпечення справедливості та зниження упередженості в системах ШІ є областю етики ШІ і зараз не регулюється.
“ШІ запам’ятає тих, хто з ним погано поводиться”. Поточні мовні моделі — це як підключений до комп’ютера вже мертвий дідусь — він пожив (навчання), але тепер його мозок просто доповнення плати, по якій біжуть на вихід електронні сигнали. Тобто пам’яті надалі у такої системи бути не може. Система працює тільки зі своїм досвідом з минулого (і навіть може вважати себе живою) і тим, що помістили на вхід в контекстне вікно (системна інструкція, питання і те, що в персоналізації ChatGPT “факти про себе”), на які дається відповідь.
З іншого боку, великі компанії копіюють собі всі наші чати, якщо на них навчити ШІ, то він уже буде “пам’ятати” про це — але там до даних застосовується анонімізація.
“У ШІ є настрій і лінь”. Хаотична поведінка ШІ може здаватися непослідовною або “втомленою”, що спонукає користувачів думати, ніби у нього є людські стани. Навіть сама OpenAI у твіттері пише про лінь моделі. Але відповіді залежать від вхідних даних (промпта), параметрів моделі та імовірнісних розподілів, отриманих у ході навчання. Моделі постійно донавчаються, і якщо чомусь розробники напартачили в налаштуваннях, їм простіше звинуватити ШІ.
“ШІ вже володіє або скоро набуде самосвідомості (стане розумним)”. Почалося це ще до буму, коли у 2022 році один з інженерів Google (Блейк Лемойне, Blake Lemoine) розмовляв з їхньою мовною моделлю (тоді ще LaMDA) про її самосвідомість і після цього виклав протоколи. Він провів тривалі бесіди, під час яких, на його думку, модель висловлювала почуття, бажання та страхи, що, як він вважав, свідчило про її свідомість. Його, звичайно, звільнили, тому що ШІ, може імітувати будь-який текст, який ми вже написали. Фантастика багато років мусолила тему самосвідомості машин, а фільми “Матриця” і “Термінатор” прописали це в масовій свідомості. Сучасні популярні ВММ так вирівняни, щоб вони не прикидалися свідомими.
Самосвідомість, суб’єктивний досвід і розумність у людському розумінні принципово відрізняється від того, як працюють сучасні мовні моделі архітектури “Трансформер (GPT)”. У них є мова і подоба мислення, але немає накопичення досвіду. Навіть, якщо ми дамо нейромережі аналог людського сну, де можна модифікувати себе, то з поточним рівнем помилок на виході вона швидше загубить себе, ніж щось усвідомить.
“Розум” у машині
Ще одна картинка з фантастики — це людиноподібні роботи, які працюють всюди, без них ми не зможемо замінити частину робіт. Багато років компанії намагалися створити такі, але виходило або погано, або дорого.
З’явився окремий клас стартапів, які сподіваються, що мультимодальні ВММ дозволять їхньому “залізу” розуміти світ і правильно виконувати завдання. Тобто стартапи створюють роботів, а не “мізки” і чекають, що ШІ стане настільки розвиненим, що зможе “жити” в роботі та керувати ним. Нові роботи повинні розуміти команди звичайною мовою і вміти їх трансформувати в ряд дій у реальному світі.

Tesla давно намагається запустити свого робота Optimus, і на останній презентації вони навіть подавали напої, але кажуть, все-таки це був не ШІ, а люди-телеоператори. У квітні 2022 року Маск заявляв, що сподівається почати виробництво до 2023 року. У березні 2025 року оголосив, що планує виробити 10–12 тисяч роботів Optimus у 2025 році.
Boston Dynamics створює Atlas, Figure AI співпрацює з OpenAI, а у Google є свій підрозділ. Amazon почала розміщувати гуманоїдних роботів Digit компанії Agility у своїх центрах обробки замовлень для пілотних проєктів. Китайські проєкти показують роботів на підтанцьовці та в кік-боях.

Крім того, люди тепер намагаються запхати ВММ і в інші пристрої — холодильники, телевізори, дрони. Є ідеї і у військову техніку це ставити. Можливо, скоро і сама фабрика буде “розмовляти”.
Коли модель нам згенерувала дурницю в чаті — це одне, а коли в роботі-дроні, що рухається по будинку (або на полі бою) — це трохи інше. Тут помилки мають ще більшу вартість і фізичну шкоду, тому поки не так агресивно маркетингом усім впарюються ці девайси.
Але був кейс. Новий клас девайсів, якій вже широко зафейлівся на нестабільності ВММ, це портативні коробочки з ШІ. Humane Ai Pin.

“ШІ замінить людей” на роботі
Якщо власники великих ШІ-компаній це кричать як позитивне явище, то політики грають на таких страхах.
Першими при зниженні вартості обчислень “з’їдяться” професії з високим рівнем повторюваних і передбачуваних завдань. Хоча все одно хтось в кінці “черги” повинен перевіряти, що на виході. Навіть якщо у нас будуть агенти, які перевіряють агентів, які перевіряють тих агентів, які роблять. Хтось же повинен перевіряти крайніх агентів.
ШІ не стільки замінить людей на роботі, скільки змінить характер їхньої роботи — просто за природою архітектури “Трансформер” (GPT) у генерації будуть помилки.

При тривалій агентній роботі ШІ додатково піднімається проблема, а чи можна виправити всі накопичувальні помилки (тобто збіжність роботи до позитивного результату). У 2023 році люди оптимістично пробували робити довгі ланцюжки завдань для GPT-3.5 (той же BabyAGI) і виходило дуже-дуже погано.
Давнє питання: якщо автопілот автомобіля помилився і когось збив, то юридичній системі держави все одно треба знайти винних і відповідальних людей. Думаю, нікого б не влаштувало, якби агент, що керує авто, давив людей і автоматично скидав їхнім родичам гроші “за шкоду” на рахунок.
Поточні “агентні” моделі, наприклад OpenAI o3, згенерують етапи відповіді і почнуть їх якось перевіряти. Якщо є конкретний алгоритм перевірки, то, звичайно, ймовірність вища, і саме так працюють “думаючі” моделі та отримують хороші результати в обмежених областях. Зараз отримання якісних відповідей займає дуже багато обчислювальних потужностей, тобто грошей.

Якщо ми не перейдемо на іншу архітектуру ШІ, то в поточному тренді зміна ландшафту роботи перетворить інформаційних працівників на відбірників згенерованих результатів, як колись багатьох людей приставили до механічних конвеєрів відбирати браковані деталі.
Це не узгоджується з обіцянкою Річарда Флориди про посилення впливу на суспільство хіпстерської креативної економіки. Ци її пік вже пройшов.
ШІ — це інструмент у людей
Багато суспільних систем зараз побудовані на тому, що людина-працівник змінює свій час-працю на гроші, за які купує собі блага, і у багатьох людей самоцінність прив’язана до цього.
Щодо соціальної рівності можна припустити, що якщо ШІ (той самий AGI) замінить працівників у деяких країнах, то капітал там стане основним інструментом, а нерівність там ще більше посилиться. Гроші будуть ефективніше “купувати” результати через оплату обчислювальних потужностей ШІ агентів.
При вкладенні капіталістами грошей в електрику і дата-центри вплив людей-працівників, заснований на їхній праці, зменшиться, оскільки їм більше не платитимуть зарплату. У таких суспільствах можливості досягти фінансового успіху своєю особистою працею значно скоротяться.
Детальніше у статті: https://www.lesswrong.com/posts/KFFaKu27FNugCHFmh/by-default-capital-will-matter-more-than-ever-after-agi
Але це більше вправа для фантазії, ніж імовірне наше майбутнє з тим суспільством, що є в ЄС.
Замінить чи в майбутньому автоматизована машинна праця працівників — це не зовсім питання технології, а більше соціально-політичне.
Локальні моделі зараз або слабкі, або вимагають дорого заліза. Тому 99,9999% людей використовують лише кілька великих ШІ-хмарних серверів, які “всмоктують” усі наші дані, і незрозуміло, як вони будуть використані цими компаніями. Безкоштовні плани (а у Deepseek і платні) затягують до себе наші дані, щоб далі дотреновувати свої моделі. Ясне регулювання конфіденційності тут у процесі створення, наприклад, Італія в перші місяці ChatGPT просто заблокувала сервіс.
В Європейському Союзі сам устрій суспільства спрямований на соціальний захист і поліпшення якості життя громадян, на противагу США/Китаю, де часто намагаються піднімати продуктивність, “викидаючи за борт” тих, хто не встигає. У США цим займається приватний бізнес, а в Китаї — державна машина.
У розвинених демократіях самі групи людей визначають правила, за якими вони живуть, отже, навіть якщо буде можливість віддати всю працю автоматизованим системам і спілкування віртуальним аватарам, це не означає, що це треба робити. Попереду нас чекають виклики регулювання використання ШІ в різних сферах життя.
А для цього ще варто широко вивчити вплив ШІ на психіку і благополуччя людей. І проблема кінцевого відповідального, як я вже говорив, нікуди не дінеться.
Потрібне й маркуваня. Якщо лікар-психолог-учитель використовує як опору ВММ, це повинно бути ясно прямо зазначено для клієнта, і той сам повинен вирішувати, до кого йти за послугою.
Авторство, творчість, копірайт
Звичайно ж, окреме пекло — це зрозуміти, що може вважатися згенерованим твором мистецтва і бути захищеним авторським правом.
Деякі суди в США поки що спираються на таке правило: якщо ШІ був використаний як один з інструментів у загальному авторському задумі, то це може бути захищено, а якщо просто як пасивна генерація — то ні.
Перші роки художники і музиканти створювали якісь протестні рухи і страйкували в США, зараз начебто все більше просто включають генеративний ШІ (Midjourney, Stable Diffusion, Suno AI) у свої робочі процеси.
У серіалі “Мандалорець” показали Люка Скайвокера, який виглядав так, як у фільмі оригінальної серії, що, звичайно, було зроблено за допомогою підміни обличчя через діпфейк ШІ. Актор Марк Хемілл був на знімальному майданчику, щоб допомогти з виконанням ролі. Для більшості фізичних рухів використовувався дублер Макс Ллойд-Джонс, оскільки він був молодшим і його статура краще відповідала молодому Люку.

Актори Голлівуду намагаються ліцензувати своє обличчя, що в майбутньому може створити проблему для нових молодих акторів, оскільки у нас будуть нескінченні, молоді й невмирущі “Бреди Пітти”. А старі зможуть, не виходячи з дому, отримувати додаткові гонорари. ШІ зможе відокремлювати оболонку актора від його реальної фізичної участі у фільмі.
В широкому контексті як повинні оплачуватися ті, на чиєму контенті тренуються моделі, — відкрите питання та набір судових справ. І як довести, що згенероване ШІ використовувало чиїсь дані: коли зображення/відео виходить у якомусь стилі, то цей стиль ШІ взяв у автора або просто згенерував його сам з нуля.
Бачив кумедні історії, знову ж таки, з розряду, коли люди не розуміють, як все працює: “я написав частину своєї книги-чернетки в ChatGPT, а потім дивлюся, хтось подібне онлайн запостив — вкрали вони моє. ChatGPT небезпечний!” 😂
Підсумок
Зараз навколо багато говорять про ШІ, і часом здається, що ось-ось він стане тим самим рятівником людства. У цю сферу вливаються величезні гроші, але будемо пам’ятати, що поки що є багато питань до реальної прибутковості та практичного широкого впровадження. Сучасні великі мовні моделі, хоч і дуже технологічні, особливо в мовних іграх, завжди будуть видавати неточні або вигадані відповіді. Це означає, що нам, як користувачам, завжди доведеться перевіряти інформацію, отриману від ШІ архітектури “Трансформер” (GPT).
ШІ-хелпери лізуть усюди — в наших телефонах, програмах, на сайтах. А наші данні відправляются в далекі хмари. Вже для більшості програмістів фокус зміщується з написання коду на його перевірку та поліпшення, а в цілому інтернет наповнюється все більшою кількістю хлам контенту, створеного ШІ. Це може ускладнити тренування нових ВММ, пошук перевіреної інформації та викликати питання до достовірності того, що ми бачимо онлайн.
Це все піднімає важливі питання про майбутнє праці в різних культурах та країнах, про те, хто несе відповідальність за помилки ШІ, і як бути з авторськими правами на контент, створений машиною.
Але зрештою, те, як ми будемо використовувати і регулювати ШІ, залежить від суспільств, тобто від нас.
🍩 Для мене дуже важливо, що ви прочитали цю статтю. Сподіваюся, що викладені в ній думки виявилися для вас корисними і, можливо, надихнули на позитивні зміни. Якщо ви відчули бажання висловити свою вдячність і підтримати мою роботу, ви можете зробити це, надіславши будь-яку суму на мою картку monobank. Навіть невелика підтримка буде для мене значущою і допоможе продовжувати ділитися своїми роздумами. Дякую! Дан 🍩